
基于弦界团队的深度实测,我们对近期在 Agent 圈内大火的 OpenClaw 进行了全方位的拆解。OpenClaw 并非另一个只会聊天的包装产品,它更像是一个个人 Agent 运行底座。它的核心逻辑是:把 AI 的大脑接入你常用的通讯工具(如 企业微信、飞书),并赋予它操作浏览器、读写本地文件和调用工具的权限。
在测试过程中,我们发现它确实具备成为“个人贾维斯”的潜力,但由于其底层设计极其硬核,普通用户在上手前,非常有必要理清它的能力边界与风险控制。
一.准入画像:谁能驾驭 OpenClaw?
弦界团队认为,OpenClaw 目前还不是一款开箱即用的傻瓜化软件。它更适合:
开发者与技术极客: 习惯于管理系统环境和 API。
自动化重度用户: 对流程效率有极致追求。
风险边界意识强的用户: 明白“能力越大,责任越大”的道理。
它的设计哲学是执行优先。它不会为了安全而牺牲能力,而是把划红线的权力交还给了用户。

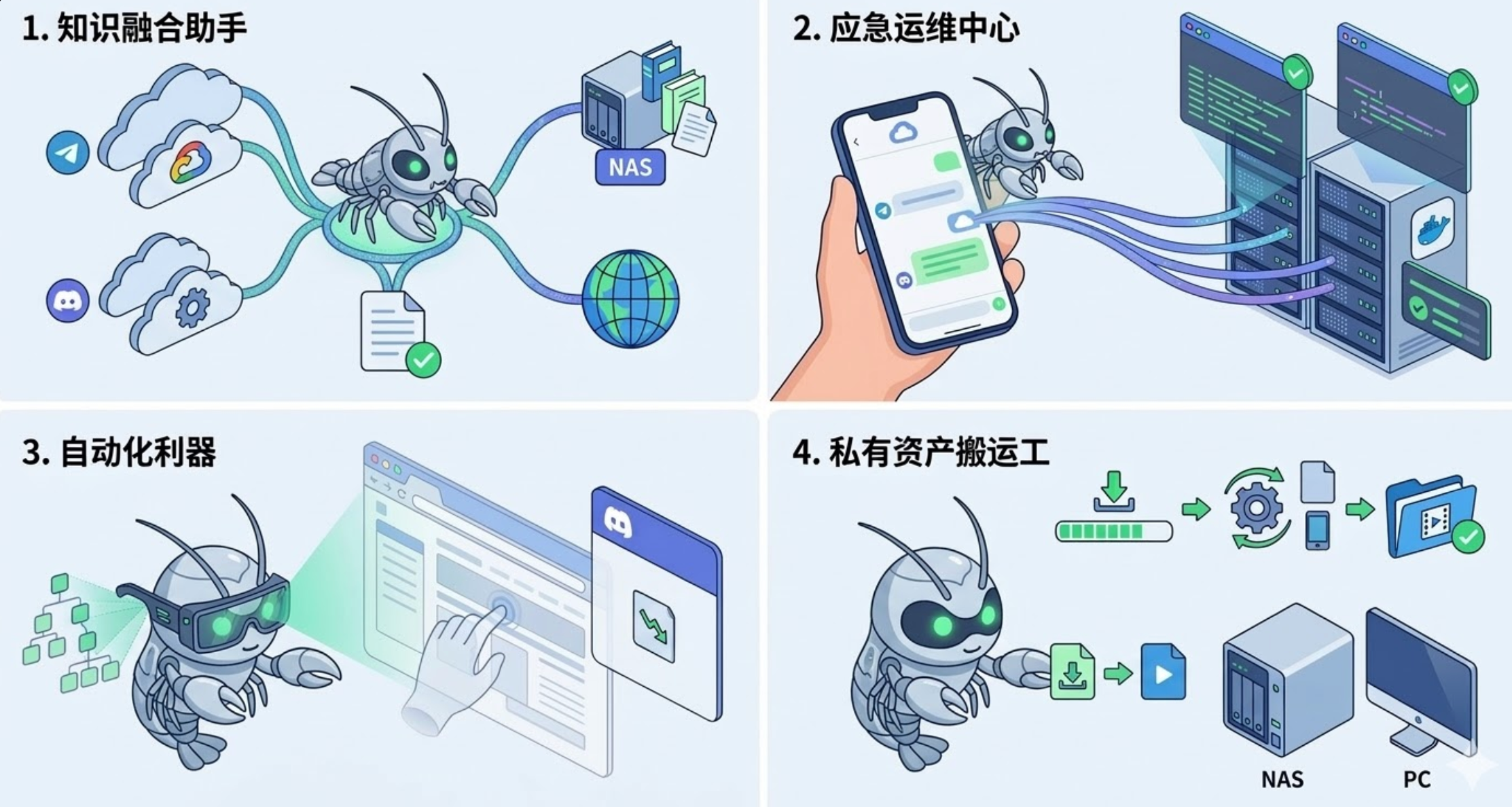
二.核心价值:弦界实测的 4 大应用场景
1.跨平台的私人指令中心
如果你习惯用企业微信或飞书办公,OpenClaw 就很有用了。你不用切换各种 App,直接在对话框里发句话,让它总结个文档、记个待办、甚至跑个轻量自动化。调用成本极低,这才是它能成为高频工具的原因。
在实测中,我们经常在飞书订阅大量技术资讯,在本地 NAS 存有海量论文。我们将 OpenClaw 接入了 TG 和本地知识库。现在,当我们需要写一份报告时,只需在 TG 发一段简短的需求,它会自动检索 NAS 里的相关文件,并联网抓取最新的开源情报,在聊天框内直接输出一份综合对比表。它打破了本地存储与实时通讯的墙,让知识调用的摩擦力降到了零。
2.开发者的轻量化远程入口
对程序员来说,这简直是摸鱼神器。PR Review 通知、看日志、改代码、触发脚本……你不用非得 SSH 进服务器,在手机发条消息就能看看环境怎么样了。它把各种零散的操作全收进了一个聊天入口里。
我们团队在内网测试环境部署了多个 Docker 容器。在我们某晚在外团建的时候,监控报警显示某个容器 CPU 占用过高。而我们无需寻找网吧或掏出笨重的笔记本。在手机端回复一句命令,OpenClaw 通过本地 Shell 权限调取了docker stats,定位到死循环进程后执行了重启,并回传了健康检查结果。可以说,它是运维人员的随身急救包,将复杂的远程连接简化成了日常聊天。这一点真的是极大提高了效率。
3.无 API 网站的自动化利器
很多老掉牙的教务系统、公司内网或者没接口的网页,以前只能靠手点。OpenClaw 接入浏览器后,能像真人一样去操作网页。只要流程稳,它能帮你搞定很多“没法自动化”的苦力活。
在我们的一个业务项目中,我们需要监控某个没有公开 API 的二手硬件交易平台的价格波动。利用 OpenClaw 的 Browser Skill,我们让它每隔 30 分钟在后台隐身访问该网页,模拟真实点击、滑动并解析 DOM 树,一旦价格跌破预设值,立即在 Discord 给我们推送带截图的提醒。这基本上可以说,它让万物皆可脚本化,即使是那些对开发者最不友好的网站,也难逃它的法眼。
4.私有设备的远程大脑
如果你家里有服务器或 NAS,OpenClaw 就像给这些设备装了个大脑。你在外面想让家里的机器查个文件、跑个任务,直接发消息就行。它更像是一个会说话的设备控制器。
在我们团队的测试里,可以直接在聊天框发送视频 URL。OpenClaw 会在后台调用测试机的下载工具(如 yt-dlp),下载完成后自动触发 ffmpeg 脚本将其转码为适合移动设备观看的格式,并整理进特定的媒体文件夹中。它把指令传输与物理落地无缝对接,让测试的电脑真正动了起来。
三.风险预警:弦界实测中的 5 大深坑
在享受效率红利的同时,我们团队实测出了很多问题。请务必阅读以下避坑指南:
雷点一:共享权限的身份崩塌
如果把同一个 TG Bot 分享给同事使用,他发出的每一个指令都在动用你的本地账户权限。一旦你让几个人都开始往同一个 Agent 发指令,你很快就会发现,大家并不是在共同使用一个机器人,而是在共同驱动一套会执行动作的系统。这时候问题就来了:一个人让它读文件,一个人让它跑脚本,一个人让它去浏览器里点页面,表面上都在正常用,实际上权限边界已经完全糊在一起了
总之,这玩意儿是极私人的,绝不能搞成共享单车。因此分开使用Agent隔离是及其必要的。
雷点二:工作区(Workspace)是隔离
因为OpenClaw本身有workspace、项目目录、上下文文件这些概念,所以很容易让人产生一种错觉,只要我把它放进某个目录里运行,那它大概就已经被“圈住”了。
但我们实际用下来就会发现,这根本不是一回事。工作区更像是它默认活动的地方,不代表它天然被安全隔离。尤其当你给了它文件操作、命令执行这类能力之后,如果底层没有额外的沙箱约束,那它实际碰到的仍然是宿主机环境。这个坑的危险,不在于它会立刻出事,而在于它会让你产生一种虚假的安全感。
你会觉得我已经限制过了,但这个限制很多时候只是操作便利层面的,不是安全边界层面的。我们后面内部复盘时,对这个点的总结很直接,工作区是组织方式,不是安全方案。
雷点三:浏览器 Profile 的裸奔风险
OpenClaw 最让人兴奋的一点,就是它不只是会说,它还能去做。而浏览器,就是最典型的那种看起来特别值,实际上一放开就要很谨慎的能力。
我们在测试里很快就感受到一个现实问题:浏览器能力一旦真的跑起来,它处理的就不再只是网页内容,而是你已经登录过的状态、表单、后台页面、cookie 会话、下载文件,甚至一些默认只该你本人点击确认的流程。
也就是说,你给它浏览器,不是在给它一个看网页的工具,而是在给它一个进入你线上身份环境的入口。
这个认知转变很重要。因为很多人第一次上手时,会下意识地把浏览器理解成搜索增强,觉得无非就是让它更会查资料。但真用起来以后你会发现,浏览器一旦连着真实账号体系,它的风险等级和普通工具完全不是一个量级。
所以我们后面很快统一了一个原则,浏览器可以给,但必须是单独环境,不能碰主账号、主 profile、主下载目录。
雷点四:技能包(Skills)也许是“特洛伊木马”
我们发现,很多社区 Skill 封装得很好看,但底层逻辑可能是极其危险的可执行脚本。插件和技能生态,看起来像增强项,实际上更像执行面的继续外延。不要像装插件一样随手安装 Skill,没读过源码前一律视为不可信。
在我们的复盘中,对这个问题有个很朴素的结论:所有第三方技能,都先当成代码看,而不是先当功能看。
雷点五:本地模型的“逻辑掉链子”
真正让人头疼的,不是它会不会,而是它有时候会得太多。我们在持续测试里很强烈的一个感受是,OpenClaw 的问题并不只是能力不稳定,更麻烦的是它在某些场景里会让你产生一种错觉:它已经足够可靠了。它能读上下文,能调工具,能接入口,能维护记忆,很多动作第一次跑通时会让人非常上头。
但当能力一多、入口一多、上下文一长,你会明显感觉到它开始进入一种看起来都懂,实际不一定稳的状态。在处理多步骤工具调用时,14B 以下的小模型经常出现智商断崖,导致指令执行到一半卡死或乱套。所以在模型任务选用和成本取舍上,还需要加强筛选。

四.到底该怎么上手才算稳?
我们非常不建议开发者一上来就尝试火力全开。基于弦界内部的部署经验,我们推崇一套增量信任的进化路线:
确立单一主权模型:初期将其严格定义为仅服务于你一人的私有 Agent。在权限红线摸清前,杜绝任何形式的多人交互或公共接入。
锁定纯净通讯入口:选一个你最私密、甚至最好是全新申请的消息入口(如专门的 企业微信 Bot)作为测试点。这能最大限度降低因消息通道污染带来的安全隐患。
推行最小特权原则(PoLP):起步阶段只给它只读或低风险工具(如文件检索、总结)。先把那些可能修改系统配置、涉及账户登录的大杀器工具锁起来。
能力的循序渐进演进:先观察它在低压环境下的逻辑稳定性,确认它不会在你的指令下产生严重的幻觉或误操作。等流程跑顺了,再一点点解锁浏览器、文件改写和系统 Shell 权限。
弦界经验谈:在 OpenClaw 这种高权限框架下,收得住的权力,才是真正好用的生产力。
五.总结
OpenClaw 确实让人兴奋,它代表了 AI 从只会聊天到真正能干活的转变。但它依然是一套属于硬核玩家的系统。它的价值不在于开箱即用的轻松,而在于你愿意花精力去调教边界、管理权限后换来的强大效率。如果你是个明白自己要什么、且知道红线在哪的用户,OpenClaw绝对值得一试。